AntMan: Dynamic Scaling on GPU Clusters for Deep Learning
摘要
AntMan利用深度学习训练的独特特性,在深度学习框架内引入了针对内存和计算的动态扩展机制。这种机制能够实现任务间的细粒度协调,并避免任务干扰,从而提高GPU的内存利用率和计算利用率。
背景
深度学习训练
深度学习的训练过程通常由数百万次迭代组成,每次迭代处理少量样本,这些样本被称为小批量(mini-batch)。通常情况下,训练一个小批量样本可以分为以下三个阶段:
- 前向传播(Forward Pass):样本数据与模型权重进行计算,生成一组得分,称为前向传播的输出
- 计算损失与反向传播(Backward Pass):
- 使用目标函数计算生成得分与期望值之间的误差,称为损失(loss)
- 损失通过模型反向传播以计算梯度,这一过程称为反向传播
- 参数更新:梯度按照优化器定义的学习率进行缩放,用于更新模型参数
前向传播的计算输出通常包含许多数据,每个数据单元称为张量(tensor)。这些张量需要暂时保存在内存中,供反向传播计算梯度时使用。此外,为了监控模型在训练过程中的质量,训练中会定期触发评估操作。
现状
GPU低利用率出现的原因:
- 深度学习生产训练任务无法在执行过程中始终充分利用GPU资源。 训练深度学习模型通常涉及一系列混合计算,其中一些计算难以通过GPU并行化,例如图神经网络中的图采样,广告系统中的特征提取,以及计算机视觉中的数据增强等。此外,在分布式训练扩展中,90%的时间可能会消耗在网络通信上。
- 常见的基于资源预留的集群调度方式导致GPU大量空闲。 这是因为深度学习任务通常无法使用部分资源。例如,随机梯度下降(Stochastic Gradient Descent, SGD)是同步的,需要所有资源同时可用来支持 “gang-scheduling”。因此,集群调度器会将部分可用资源闲置以等待满足所有请求。
基于MPS的打包策略不好,原因在于:
- 性能保障任务的需求必须得到满足。虽然提高GPU利用率很重要,但确保关键任务(即有资源配额的任务)的性能同样至关重要。在同一GPU上并行执行多个任务可能引发干扰,从而显著降低关键任务的性能。
- 任务打包策略可能引发内存竞争。并发任务间的内存竞争可能导致训练任务失败,尤其当任务的资源需求突然增加时。
因此,目前的生产GPU集群通常采用资源独占分配的方式,避免资源竞争和性能下降的风险:
-
团队调度造成空闲等待:
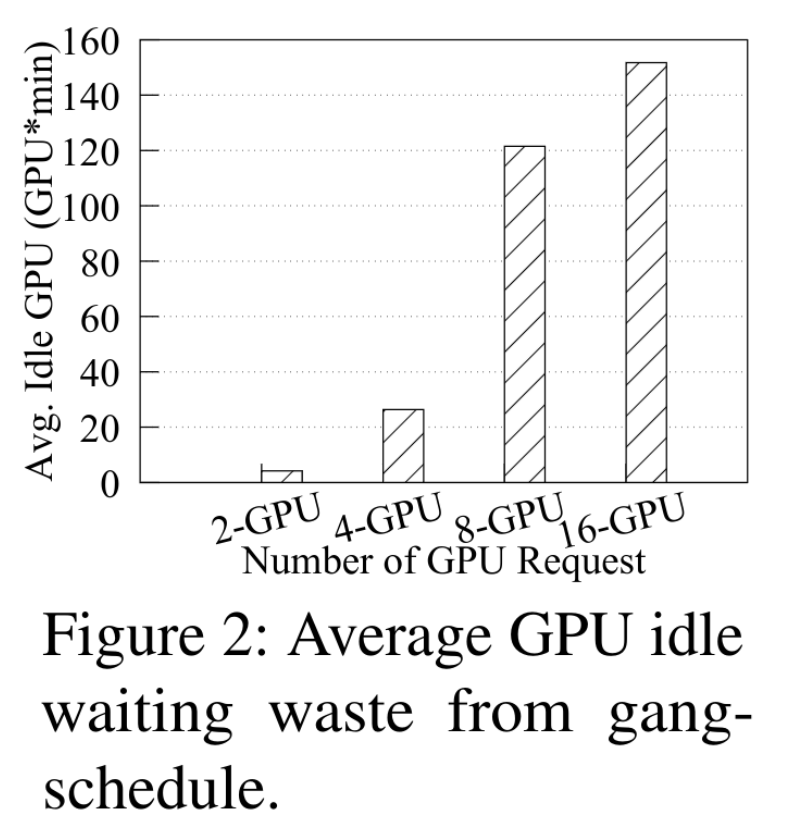
- 在处理大规模数据时,分布式多GPU训练是必不可少的。这类任务需要团体调度(Gang-Scheduling),即任务在所有所需GPU同时可用之前不会启动训练
- 例如:如果一个4-GPU的任务需要资源,而集群中仅有3个GPU可用,则这3个GPU必须等待最后一个GPU,就会处于空闲等待状态
- 任务所需的GPU越多,因部分资源预留导致的空闲GPU浪费就越多
- 弹性训练的潜力与局限:
- 近期,弹性训练(如 TorchElastic)被提出以适应增量式的资源分配
- 问题:在生产环境中弹性训练很少被使用,因为它会引入不确定性,影响模型的准确性
-
生产环境中的DL管道经常表现出类似的任务内资源需求动态变化,导致资源需求难以预测
-
某些任务会周期性地变为CPU密集型任务,如神经机器翻译任务中的观察
- DL任务通常需要按峰值资源需求进行分配,导致昂贵的硬件资源被低效利用
数据并行训练
为了训练大规模数据集,深度学习通常采用数据并行性(data parallelism),在多个GPU上进行任务分布:
- 每个GPU负责处理数据的一个子集,并行进行计算
- 每个小批量处理后,在模型更新之前,各GPU间需要进行梯度同步操作
观察
文章通过实验,论述Key Insight:大部分模型本身占用的显存并不多,使用的显存多来自mini-batch过程中,在单个mini-batch中会被申请和释放。文章中所有的design基本都是围绕这一Key Insight展开的。
模型规模和小批次(mini-batch)训练过程中的特点:
- 模型尺寸小,内存需求主要来自临时分配:
- 尽管一些 GPU(如V100和A100)支持高达32-40GB的显存,DL模型实际占用的显存较少
- 数据显示,90%的DL模型只需占用500MB的显存。这意味着:
- 大部分显存用于临时分配(如小批次数据和中间计算张量),而非模型本身
- 这些临时显存会在同一小批次周期内分配和释放
- 小批次周期短:
- 数据表明,80%的任务在600毫秒内完成一个小批次的处理。这种短周期为细粒度资源调度提供了机会
- 小批次计算重复性高:
- 小批次的计算过程通常具有高度相似性,便于对任务性能进行动态分析和预测
- 基于小批次的进度率(progress rate),可以量化任务之间的干扰程度,作为调度决策的性能指标
设计
文章联合设计了调度器和框架,让框架来在训练任务的角度支持显存和算力的动态调整,然后让调度器从集群的角度利用这一新的特性进行更有针对性的调度。
框架上
内存
GPU内存的动态扩展:GPU内存是DL作业中最稀缺的资源,其分配通常面临以下问题
- DL框架在作业启动时会预先分配大量内存以满足最坏情况下的需求,导致资源浪费
-
内存需求在作业运行过程中可能出现波动,如果超出分配量,作业会失败
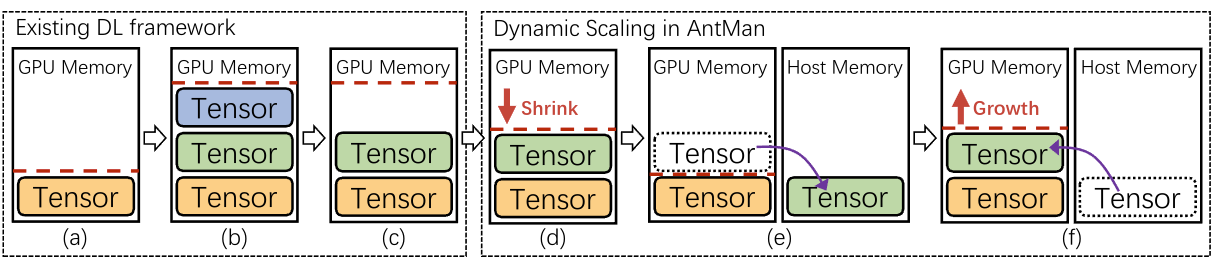
AntMan采用了扩展GPU内存上限的方法。它主动检测正在使用的内存,缩小缓存内存以自我调整GPU内存使用到适当的水平。(依赖处理mini-batches时监控应用的性能和内存需求)
通过将张量在显存和主存移动,实现动态内存管理。
计算
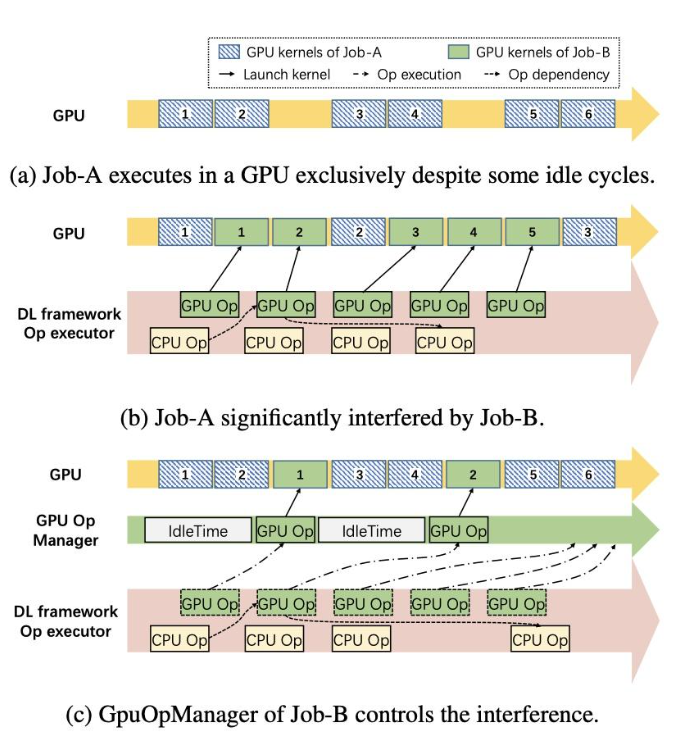
在计算方面,如果多个任务运行在同一个GPU上时,主要会带来GPU Kernel的排队延迟,和PCIE总线带宽的争抢。以下图(a)和(b)来说,B任务影响了A任务原本的执行,为了解决这个问题,Antman在框架层引入了GPU Op Manager。在原本的设计中,一旦Kernel的控制依赖被满足了,就会被执行。GPU Op Manager接管了原本的流程,它会控制GPU Kernel被issue的频率。因为GPU Op Manager只会管控GPU Kernel,因此CPU的Op可以照常被执行,不会被Block。如下图(c)所示,满足了依赖的CPU Op可以在GPU Op没有被执行的时候照常执行,不会受到GPU Op Manager的影响。
调度器上
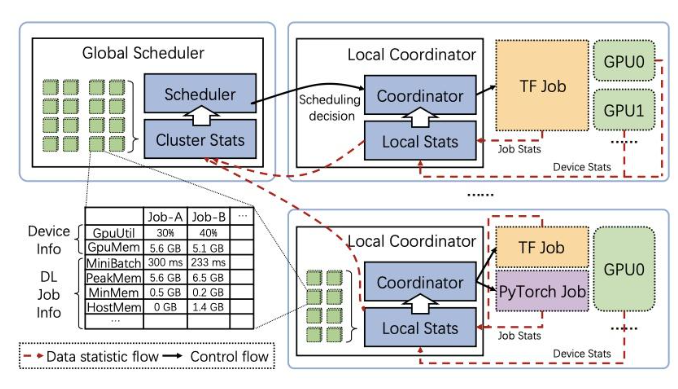
在调度器的设计上,Antman并没有采取Monolithic的架构,而是存在两个角色:Global Scheduler和Local Coordinator。
其中全局的调度器负责进行任务的调度
而Local Coordinator主要负责根据深度学习的训练任务的执行情况(任务情况,硬件指标,mini batch的执行时间,显存和内存的使用情况等),管理训练任务的全生命周期
Antman根据SLA把任务分为resource-guarantee和opportunistic两种任务,其中前者需要保证与独占GPU卡类似的训练速度。Antman的设计目标是在保证resource-guarantee类型任务的SLA的同时,提高集群的利用率opportunistic类型的任务主要就是用来提高集群利用率的。
全局调度器的调度算法比较简单,如下图所示。首先调度器会根据拓扑,获得一个最优的节点组合。这一步与业界主流基本一致,尽可能考虑到NVLink等硬件资源的拓扑结构,进行分配。如果是resource-guarantee的任务,有合适的节点就会直接运行。对于opportunistic类型的任务,Antman会找到负载最低的节点,去执行。

Local Coordinator最主要的职责是管理在共享的GPU上训练任务。在Antman中,一个GPU只会被分配给一个resource-guarantee的任务。所以当有opportunistic的任务已经在GPU上运行时,为了满足新来的resource-guarantee任务,Local Coordinator会限制opportunistic任务使用的 SM 和显存。随后慢慢提高opportunistic的限制,确保在不影响resource-guarantee任务的训练速度(mini batch 的耗时)的同时,提高opportunistic的资源限额。