DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
现状
一个端到端的LLM查询可能显著更慢,服务提供商不得不超额配置计算资源,尤其是大量GPU,从而导致成本效率不足。因此,在确保较高服务级别目标(SLO,即满足延迟要求的请求比例)的前提下,优化每次LLM查询的成本正变得日益重要。
一个LLM服务通过两个阶段响应用户查询:
- 预填充阶段(Prefill Phase):处理用户的提示(由一系列标记组成)以一步生成响应的第一个标记
- 处理较长的用户提示时,是计算受限的,处理一个512标记长度的序列会使一块A100 GPU几乎达到计算瓶颈
- 解码阶段(Decoding Phase):随后逐步生成后续标记;每次解码步骤基于之前生成的标记生成新的标记,直到到达终止标记为止
- 解码阶段尽管每步只处理一个新标记,但却与预填充阶段需要类似的I/O操作量,因此其性能往往受限于GPU的内存带宽
LLM服务延迟的两个关键指标:
- 首个标记时间(Time to First Token, TTFT):预填充阶段的时长
- 每个输出标记时间(Time Per Output Token, TPOT):除首个标记外,每个请求生成一个标记的平均时间
不同应用对这两个指标的需求不同。例如,实时聊天机器人优先追求低TTFT以实现快速响应,而TPOT的优先级仅需快于人类阅读速度(即250词/分钟)。相反,文档摘要生成则强调低TPOT以加快摘要生成速度
问题
在prefill和decode阶段中,每个标记位置都会生成中间状态,称为KV缓存(Key-Value Caches)。这些缓存会在后续解码步骤中重复使用,为避免重新计算,它们会保存在GPU内存中。由于LLM权重和KV缓存共享GPU内存,大多数LLM推理引擎选择将预填充和解码阶段并置在GPU上,尽管两阶段的计算特性截然不同 。现有的LLM服务系统通常将这两个阶段的计算放在一起,并对所有用户和请求进行预填充和解码的批处理计算。这种策略不仅会导致预填充与解码之间的严重干扰,还将两阶段的资源分配和并行化方案紧密耦合在一起。 面对严格的延迟要求,现有系统往往不得不在两种延迟间取舍,或是过度分配计算资源以满足两者的需求
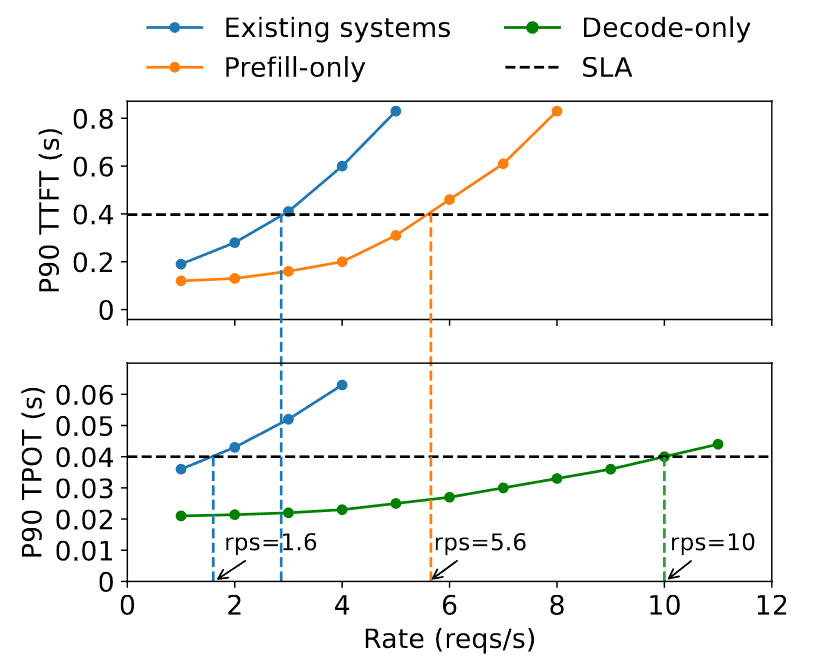 (这个实验,在一块GPU上同时做prefill和decode,当然要比只做prefill/decode效果差,实验是否有说服力?)
(这个实验,在一块GPU上同时做prefill和decode,当然要比只做prefill/decode效果差,实验是否有说服力?)
预填充(prefill)和解码(decoding)阶段的并置会导致严重的干扰:
- 预填充与解码之间的资源争用
- 难以满足差异化延迟需求以及并行化策略
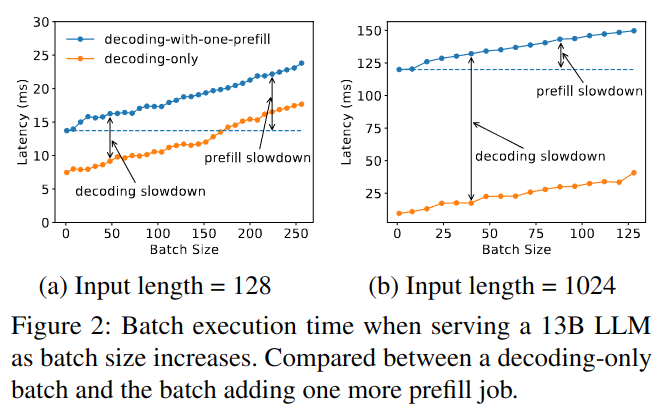
解决方案
将LLM推理的预填充和解码阶段解耦,并分别分配到不同的GPU上:
- 独立运行各阶段的计算完全消除了预填充-解码干扰
- 允许每个阶段根据自身的延迟需求,通过量身定制的资源分配和模型并行化策略独立扩展
细节
模型并行策略:不同的场景下,可能对TTFT和TPOT的需求不一样,那么Prefill和Decode的并行策略可能不同。
- 假如服务对TTFT较严格,对TPOT需求较低,那么Prefill阶段更倾向使用Tensor Parallelism(简称TP,操作内并行)
- 而Decode阶段更倾向使用Pipeline Parallelism(简称PP,操作间并行)提高吞吐
但现有的服务架构Prefill阶段和Decode阶段会共享模型并行策略。
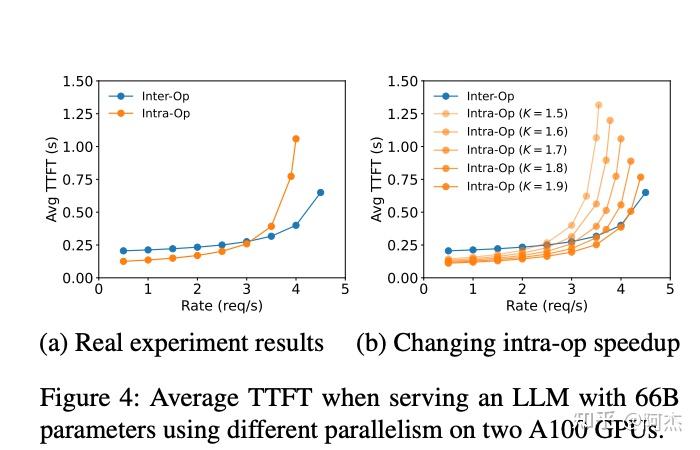
并行策略对不同阶段的影响
作者通过实验介绍TP、PP对不同阶段的影响程度,探究Prefill和Decode到底使用什么模型并行策略更优。其中 inter-op表示PP,intra-op表示TP
- Prefill阶段:在低流量场景,使用TP策略,TTFT更低;当流量增大时,TP策略对应的TTFT增加越快,流量超过一个阈值后,PP对应的TTFT会更小。所以对于Prefill阶段,如果有更低的TTFT需求,可以把TP degree设大一点,并且配置更多的GPU
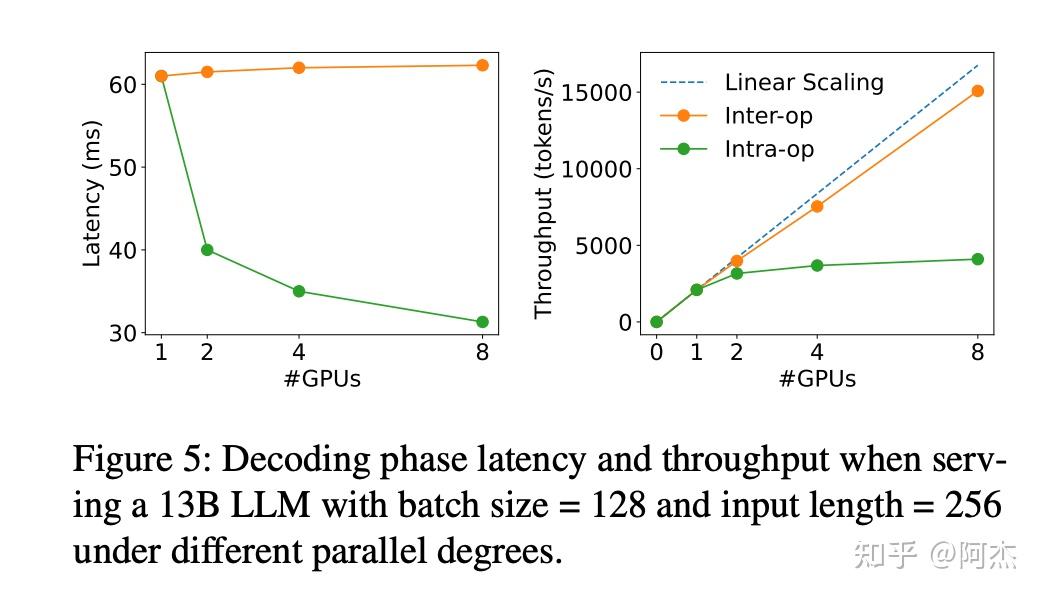
- Decode 阶段:对于TP来说,Latency可以靠TP degree scale down,但Throughput不能scale up;对于 PP来说,Latency基本不能靠PP degree scale down,但Throughput接近 scale up
搜索Prefill、Decode最优模型并行配置
- 单机搜索
暴力模拟
- 跨机搜索
当模型过大的时候,可能单机无法完全放下一个Prefill Worker和Decode Worker。例如OPT 175B,一个服务实例使用BF16存储需要占用350 GB显存,两个服务则要占用700 GB显存,这个显存目前没有一个单机可以放下(A100或者H100 8x80GB)。对于这种模型,KVCache迁移的时候需要跨机传输,迁移耗时则会大幅增加。
为了避免迁移开销上升,需要合理放置Worker。KVCache按层存储,所以只要保证Prefill和Decode Worker相同层的KVCache在同一个机器内,KVCache迁移就不会出现跨机传输。
所以对于较大模型,可以把模型按层划分多段,每段放到不同机器,不同段的模型采用PP,然后再对同一段的模型进行单机的模型并行策略的搜索。这样跨机传输仅出现在PP层间,不会出现在KVCache迁移,也保证了KVCache迁移开销始终低于Decode一个tokens的开销。