Orion: Interference-aware, Fine-grained GPU Sharing for ML Applications
现状
- 尽管DNN计算具有高度的计算和内存密集型特性,但单个DNN工作负载通常并未充分利用GPU硬件
- 时延敏感的推理任务(自动驾驶、欺诈检测和推荐系统) -> 难以充分利用计算单元
- 训练任务,但批量大小会影响模型的收敛性 -> 难以充分利用显存
- 使用扩展数据预处理消除数据停滞,使用异步更新、梯度压缩和网络内聚合来减轻通信停滞 -> 还不够
常见的解决方案:
- 时间共享,以推理请求或训练小批次的粒度来对GPU进行时间切片。这种方法可能导致队头阻塞,因为新进入的推理请求或训练小批次必须等待正在执行的任务完成后才能被调度,并且当个别任务的操作未充分占用GPU计算或内存带宽时,资源仍被浪费
- 空间共享,现有技术或是粒度过粗(MIG、Zico、Tick-Tock)、或是对干扰考虑不足(MPS、GPU Streams、REEF、Paella)
观察
GPU计算吞吐量和内存带宽的利用率呈现突发性,而平均利用率较低
GPU计算利用率的峰值通常与内存利用率的峰值不同步
DNN workloads consist of many kernels with different resource requirements.
- 计算密集型
- 内存密集型
由于数据依赖性,单个DNN任务的内核通常顺序执行,因此当一个内核使GPU计算或内存带宽达到饱和时,往往会在短时间内使其他GPU资源闲置
方法
将具有相反资源需求的内核进行共置,虽然由于数据依赖性,DNN 工作负载中内核的执行重叠是有限的,但可以将来自不同任务的内核进行共置
计算密集型任务:Conv2d 内存密集型任务:BN2d
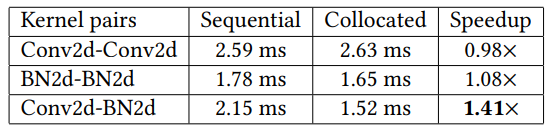
为了最大化利用率,需要在DNN任务之间共享GPU:空间共置对于具有相反计算和内存密集型的内核最为有效。由于DNN任务包含计算密集型和内存密集型内核,将来自不同DNN任务的相反资源需求的内核进行共置有助于提高利用率,同时最小化干扰
Orion
提出Orion,一种细粒度、干扰感知的GPU调度器
Orion的目标是在保持高优先级作业的高性能的同时,利用空闲的GPU资源来执行低优先级的作业
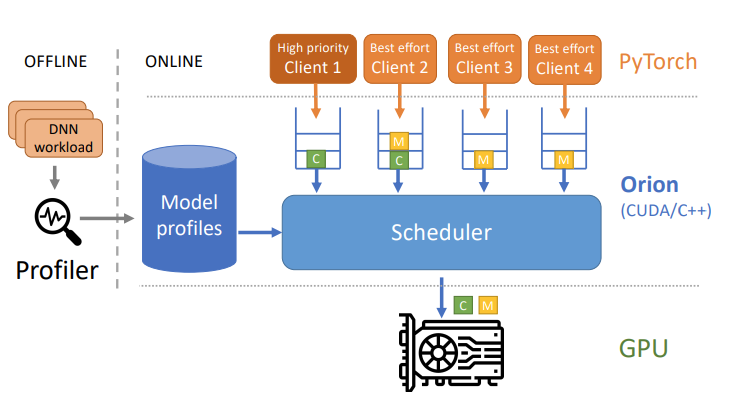
Orion拦截每个客户端提交的GPU操作(包括计算kernels:卷积、批量归一化;内存管理:内存分配、内存复制)
Orion将根据文中提出的调度策略,利用在离线工作负载分析阶段收集的内核特征,从每个客户端的软件队列将操作提交给GPU硬件
Orion的调度策略提前知道:
- 内核的计算强度
- 内核的内存强度
- 每个尽力而为任务内核的预期执行时间
- 每个尽力而为任务内核的SM需求
在执行前,Orion会离线分析每个DNN(深度神经网络)工作负载,并生成一个包含模型中每个内核的分析信息的文件。然后,Orion调度器将这些分析信息加载到内存中的查找表中,通过唯一的内核ID进行索引。
Nsight Compute -> 获取GPU Kernels所需的块数、每个块的线程数、每个线程的寄存器数以及所需的共享内存
Nsight Systems -> 区分计算密集型或内存密集型GPU Kernels
Others
这篇文章的调度策略极大依赖于离线处理获得的前置信息,包括高优先级任务的请求延迟(这是在高优先级任务单独运行在专用GPU时进行的分析)